




![YQJ~%XPWQ`X]4U}KO])V[}A](http://www.17diaoyan.com/file/upload/201609/24/11-48-06-98-21.jpg)
一晃三年过去,笔者对于大数据也有了一些新的认识, 无论是所谓的大数据带来了思维方式上的变革,还是技术上的革命,或者商业模式或管理模式的改变,但从本质的角度讲,大数据还没有达到所谓的高度,即大数据时代,其与信息时代的计算机、集成电路、光纤通信,互联网相比,目前还无法媲美,衡量大数据成功的标志,是是否推动了国家的人均信息消费水平达到一个新的高度(此句摘自李国杰院士)。
对于《大数据时代》此书提的很多观点应该用辩证的方法来看待,以下笔者就一些认识上的一些争议给出自己的理解,注意,后面有彩蛋,一定要看完哦:
Part 1
“不是随机样本,而是全体数据”,实际大多并不是这样
作者表达了一个观点,“当数据处理技术已经发生了翻天覆地的变化时,在大数据时代进行抽样分析就像在汽车时代骑马一样。一切都改变了,我们需要的是所有的数据,“样本=总体””。
这种说法表明了一种新的认知世界的方式,是一种新的趋势,努力达到全量的确可以让我们抓到了更多的细节,让我们摆脱传统统计分析学的束缚,就好比以前预测美国总统大选,采用的是民意抽样统计,而如今已经可以对于社区用户所有言论的判断来更精准的预测。
但是,现实世界很残酷,大多数领域你其实无法拿到全量的数据,或者,如果你要拿到全量的数据,代价极其巨大,因此,大多数时候,我们用的大数据仍是局部的小数据,没有所谓“样本=总体”的条件,传统的以抽样来理解这个世界的方式仍然有效,机器学习与统计学作为一种认知世界的方法也将持续有效,前期的AlphaGo与李世石的人机大战。AlphaGo只能用采样的方式获得有限的棋局进行深度学习就是例证,因为你不可能拿到全部的样本或者甚至是足够的样本,因为这个数量比全宇宙的原子还多。
当然,对于国际象棋和中国象棋上,全量的数据已经使得传统胜负的玄妙缺失了意义,因此,可以这么大胆推测,当某个领域具备“样本=总体”的时候,就是该领域被大数据替换的时刻。
Part 2
“不是精确性,而是混杂性”,没能力但不能否定精确性的价值
作者表达了这样一个观点,执迷于精确性是信息时代和模拟时代的产物。只有5%的数据是结构化且能适用于传统数据库的。如果不接受混乱,剩下95%的非结构化数据都无法被利用,只有接受不精确性,我们才能打开一扇从未涉足的世界的窗户,大数据的简单算法比小数据的复杂算法更有效。
传统数据处理追求“精确度”,这种思维方式适用于掌握“小数据量”的情况,因为需要分析的数据很少,所以我们必须尽可能精准地量化我们的记录。大数据纷繁多样,优劣掺杂,分布广泛。拥有了大数据, 我们不再需要对一个现象刨根究底,只要掌握大体的发展方向即可,适当忽略微观层面上的精确度会让我们在宏观层面拥有更好的洞察力。
这段话说得没错,但我认为大数据的复杂算法对于认识这个世界更为重要,对于精准性的把握始终是我们的目标,只是因为我们现在的算法太弱了,无法驾驭大数据,才提简单的算法。
比如,在工业界一直有个很流行的观点:在大数据条件下,简单的机器学习模型会比复杂模型更加有效。例如,在很多的大数据应用中,最简单的线性模型得到大量使用。而最近深度学习的惊人进展,促使我们也许到了要重新思考这个观点的时候。简而言之,在大数据情况下,也许只有比较复杂的模型,或者说表达能力强的模型,才能充分发掘海量数据中蕴藏的丰富信息。运用更强大的深度模型,也许我们能从大数据中发掘出更多有价值的信息和知识。
为了理解为什么大数据需要深度模型,先举一个例子。语音识别已经是一个大数据的机器学习问题,在其声学建模部分,通常面临的是十亿到千亿级别的训练样本。在Google的一个语音识别实验中,发现训练后的DNN对训练样本和测试样本的预测误差基本相当。这是非常违反常识的,因为通常模型在训练样本上的预测误差会显著小于测试样本。因此,只有一个解释,就是由于大数据里含有丰富的信息维度,即便是DNN这样的高容量复杂模型也是处于欠拟合的状态,更不必说传统的GMM声学模型了。所以从这个例子中我们看出,大数据需要复杂深度学习,毫无疑问AlphGo也必定是欠拟合的。
Part 3
“不是因果关系,而是相关关系”,追求真理是我们永恒的目标
作者提出了这样一个观点,寻找因果关系是人类长久以来的习惯。即使确定因果关系很困难而且用途不大,人类还是习惯性地寻找缘由。在大数据时代,我们无须再紧盯事物之间的因果关系,不再把分析建立在早已设立的假设的基础之上。而应该寻找事物之间的相关关系,让大数据告诉我们“是什么”而不是“为什么”。
一方面,应该承认基于大数据的相关关系是我们认识世界和改造世界的新的方式,从应用科学的角度讲,降低对于因果关系的追求可以让大数据创造更大的价值。
另一方面,当前阶段由于我们对于世界的认知太少,人类在有限的时间内不可能找到“终极真理”,大量的规律通过大数据暴露出了蛛丝马迹,即所谓的相关关系,但其本质上仍是因果关系的体现,因此两者并不冲突。一个解决当前问题,是近,一个解决长期问题,是远,两者相辅相成,无所谓谁替代谁。从社会角度来讲,企业可以致力于大数据相关关系来创造更多的商机,而因果关系仍然是基础研究需要追求的东西,不能说人类物质上满足了,就不去追求更为本原的东西。
同时,大数据方法也可以发现因果关系,2014年,美国国防高级研究计划局启动其“大机理”项目。目的是发展可以发现隐藏在大数据中因果模型。典型“大机理”例子就是,1854年的伦敦地图显示爆发霍乱和污染的公共水泵之间的联系。该发现推翻了当时认为疾病是通过空气传播的认识。大机理包含在巨大的、零碎的、有时相互矛盾的文献和数据库中,所以,没有任何一个人可以理解该如此复杂的系统,所以必须依靠计算机。
DARPA办公室最初使用“大机理”工具来研究导致细胞癌变的复杂分子之间的相互作用。该方法包括使用电脑扫描癌症类论文,来获取癌症路径的有关数据。获取的数据片段可以组成”前所未有规模和精度”的完整路径,以此来确定传递路径如何互动。最后,自动工具可以帮助确定因果关系,该因果关系可用来开发潜在治疗癌症的方法。科恩说:“分子生物学和癌症文献强调机理,论文描述蛋白质如何影响其它蛋白质的表达,这些影响如何产生生物效果。电脑应该可以被用来分析这些癌症类论文中的因果关系。”通过强调因果模型和解释,大机理将成为科学的未来。
Part 4
“小数据的问题,大数据就能解决”,大数据并没有解决小数据问题
大数据体现了4V特征,但我们现在碰到的数据仍是主要是小数据,我们应该抱着务实的态度去解决小数据的问题,小数据的问题并不会由于大数据的产生而自动解决。
统计学家们花了200多年,总结出认知数据过程中的种种陷阱,这些陷阱并没有被填平,比如采样,大数据中有大量的小数据问题,这些问题不会随着数据量的增大而消失,要注意数据(样本)的偏差,比如Google的流感预测为什么近3年失败,因为其随机性实际不够,比如媒体对于流感流行的报道会增加与流感相关的词汇的搜索次数,进而影响Google的预测,对谷歌大肆炒作的流感跟踪系统的研究结果发现,该系统多年来一直高估美国的流感病例。这项失败凸显了依赖大数据技术的危险性。
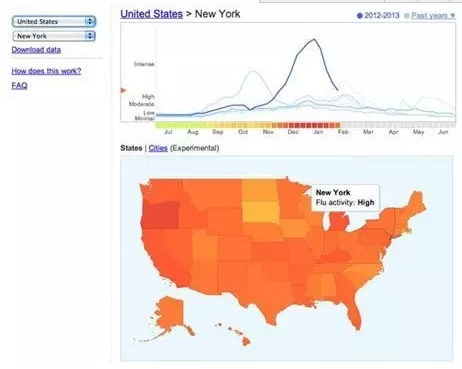
“谷歌在2008年推出的流感趋势系统监测全美的网络搜索,寻找与流感相关的词语,比如“咳嗽”和“发烧”等。它利用这些搜索来提前9个星期预测可能与流感相关的就医量。在过去3年,该系统一直高估与流感相关的就医量,在这类数据最有用的流感季节高峰期尤其预测不准确。在2012/2013流感季节,它预测的就医量是美国疾控中心(CDC)最终记录结果的两倍;在2011/2012流感季节,它高估了逾50%。”
Part 5
发人深省的彩蛋观点,关于啤酒和尿布有点雷
(1)数据化,而不是数字化
所谓的数字化指的是把模拟数据转换成用0和1表示的二进制码,而数据化是指把现象转变成可制表分析的量化形式的过程,举个例子,我们扫描实体书成为电子书,如果保存形式是图片,这个只能叫作数字化,而我们通过字符识别软件进行了文本解析,图像就变成了数据化文本,两者有本质的不同,万物只有数据化后,才可以被量化,我们才能通过量化后的数据创造更多的价值。美国政府在提数据开放的时候,强调了开放的数据必须是可以有机读的,就是这个意思,一个PDF的信息量跟一个WORD的信息量显然是不一样的。
(2)应用为王,不要迷信技术
目前各类企业都在建设大数据中心,但成本其实很大,当前的新的信息技术层出不穷,不断冒出新概念,新名词,大数据技术其实还在不停的发展,现阶段,应该充分考虑成本因素,抱着应用为先的态度,技术始终要为应用服务,我们应该致力于用技术解决业务问题,而不是被潮流技术牵着鼻子走。不用迷信Google等技术公司的创新,有的放矢的借鉴,BAT做得足够好,不要去贬低这些公司的技术创新性,不要用Google的AlphGo去鄙视百度的人工智能,应用始终为王,百度发明的人工智能输入实际应用意义可能远大于AlphaGo。
(3)隐私问题,不是那么简单
告知与许可也许已经是世界各地执行隐私政策的基本法则,但这个法则有问题,大数据时代,很多数据在收集时并无意用于其它用途,但最终往往是二次开发利用创造了价值,公司无法告知用户尚未想到的用途,而个人也无法同意这种尚是未知的用途。如果谷歌要使用检测词预测流感的话,必须征得数亿用户的同意,就算没有技术障碍,有哪个公司能负担得起。
同样,所谓的匿名化在小数据时代的确可以,但是随着数据量和种类的增多,大数据促进了数据内容的交叉检验。
政府在未来制定相关法规的时候,应该充分尊重事实,也许提前预防永远无法解决大数据应用和隐私问题。
(4)大数据的驱动效应
大家所说的大数据是沙里淘金,大海捞针,导致人们总是渴望从大数据挖掘出意想不到的“价值”。实际上大数据更大的价值是带动有关的科研和产业,提高个行业通过数据分析解决困难问题和增值的能力,大数据价值体现在它的驱动效益。
所谓的“啤酒与尿布”的数据挖掘经典案例,其实是Teradata公司的一位经理编造出来的“故事”,历史上并没有发生过,这个天雷滚滚啊。
冯.诺依曼指出:“在每一门学科中,当通过研究那些与终极目标相比颇为朴实的问题,发展出一些可以不断加以推广的方法时,这门学科就得到了巨大的进展。”在发展大数据技术和产业中,不应天天期盼奇迹出现,而应扎实多做“颇为朴实”的事,培育数据文化,打造大数据应用环境,提高决策合理性,开拓新的数据应用。(此段引述李国杰院士的报告)
深有感触,大数据推动了企业的数据文化,大家对于数据有了新的认识和充分的尊重,即使我们在用得大多仍然是小数据,那又如何,只要我们的心中的数据已经足够大。